Motivation
How we humans perform dense object packing.
Imagine packing an item into a nearly full suitcase. As humans, we typically first form a visual representation of the scene and then make attempts to insert the object, feeling the compliance of the objects already inside to decide where and how to insert the new object. If a particular region feels soft, we can then apply additional force to make space and squeeze the new object in. This process is natural for us humans but very challenging for current robotic systems.
Humans performing a wide range of complex daily manipulation tasks. Our ability to integrate visual, tactile sensing and make future predictions is crucial for many daily tasks. For example, when we peel an orange, we sense how thick the peel is to determine how much force to apply.
In this work, we seek to endow robots the capability to understand physical environments comprehensively with tactile and visual sensing.
Method Overview
RoboPack is a framework that integrates tactile-informed state estimation, dynamics prediction with model predictive control for manipulating objects with unknown physical properties.
At the core of our framework is a particle-based representation that contains visual, tactile, and physics information.
Illustration of constructing our particle-based scene representation.
With this representation, we are able to learn state estimation and dynamics prediction for planning.
High-level sketch of our state estimation, dynamics learning, and planning pipeline.
One feature of this framework is that, we only need one visual frame to initialize the system, and only tactile feedback is required throughout the episode. This resembles humans' ability of manipulating objects without really looking at the scene (e.g., when talking to a person), and effectively sidesteps the difficulty of obtaining complete visual observation of the world when severe visual occlusions are present.
Experimental Setup
We compare our approach against baselines, including prior work on dynamics learning (RoboCook), ablated versions of our method (w/o tactile, w/o state estimation), and physics simulator-based planner on two challenging tasks:
1. Non-Prehensile Box Pushing: The robot holds a tool, e.g., a rod, to push a box to a target pose. It is much more challenging than a normal object pushing task, because (1) the robot gripper is very compliant and the tool is only loosely held, making the interaction between tool and box complex, and (2) we manually placed calibration weights inside the box to adjust its mass distribution, making dynamics highly uncertain.
2. Dense Packing: The robot places an object inside a visually densely packed box. It needs to interact with the environment to understand the physics properties (e.g., movability and deformability) of objects inside the box to create space with suitable actions in order to place the object in the free space.
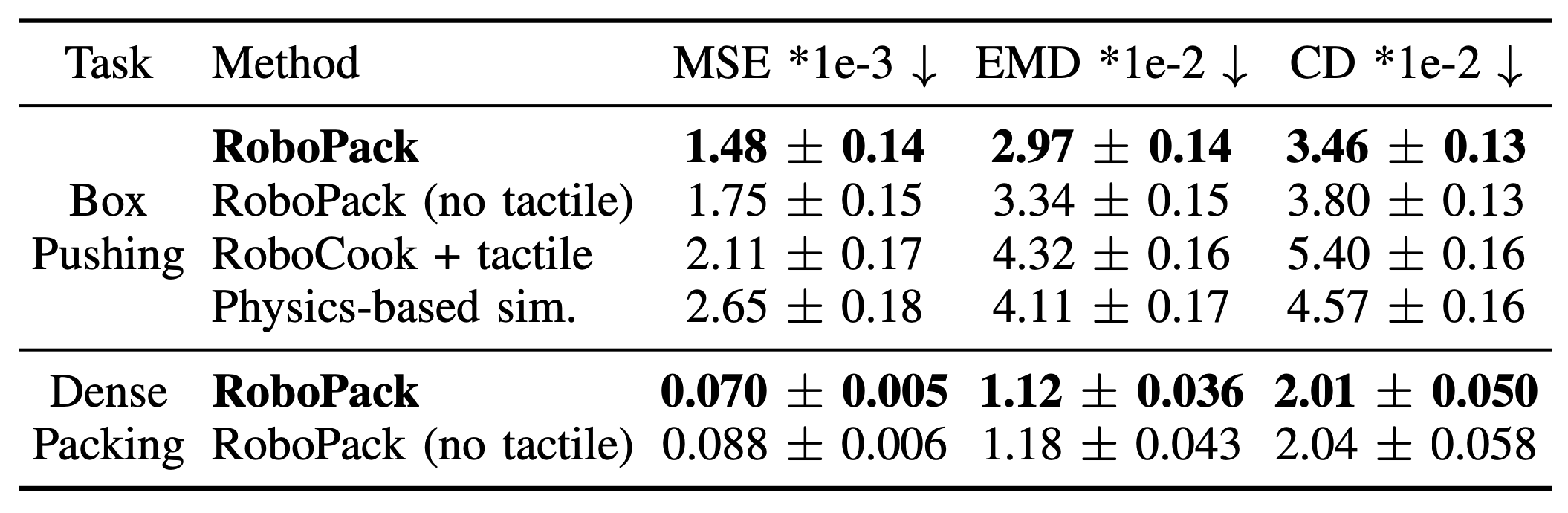
Dynamics Prediction Performance
We first evaluate our method on dynamics prediction for two tasks.
Long-horizon dynamics prediction results on the two task datasets. Errors represent a 95% confidence interval.
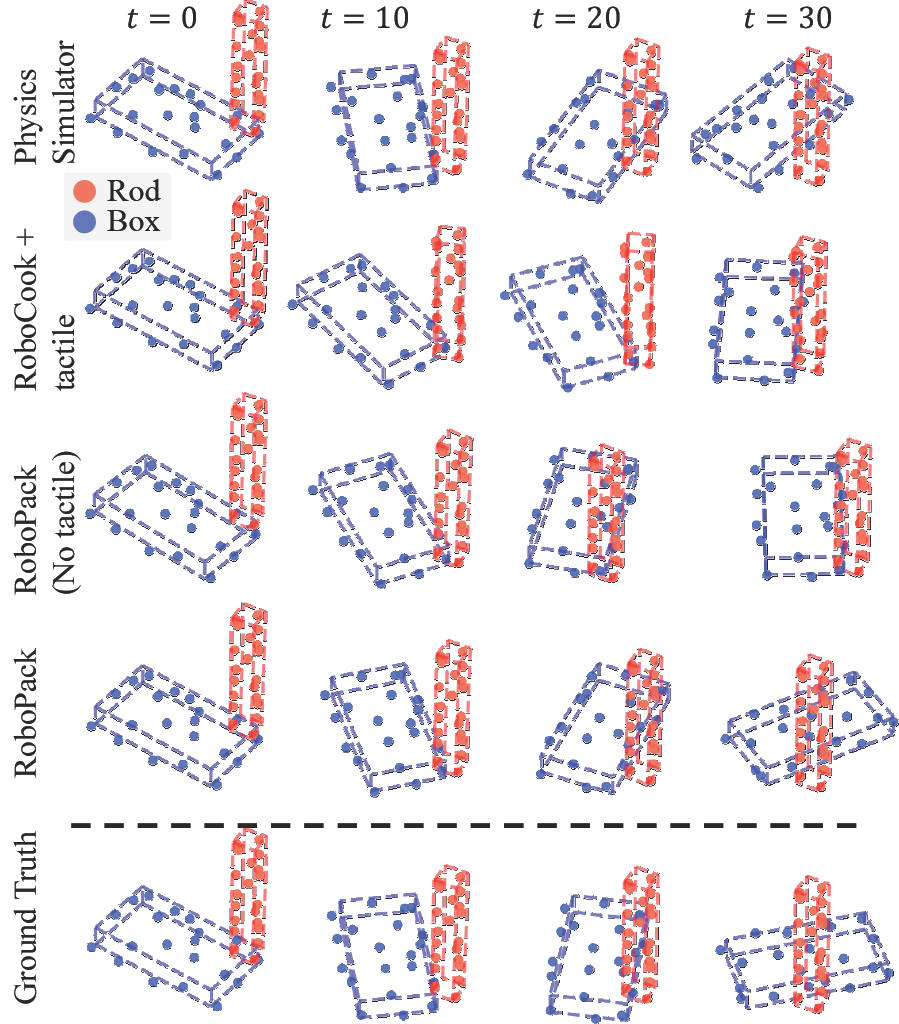
Qualitative results on dynamics prediction.
Analysis of Learned Physics Parameters
What do the latent physics vectors learn? To answer this question, we collect the latent vectors generated during the box pushing task and perform a clustering analysis.
PCA visualizations at four distinct timesteps show that the physics parameters gradually form clusters by box type. We also employ a linear classifier trained on these parameters to accurately predict box types to demonstrate these clusters’ linear separability. The classifier’s improving accuracy across timesteps underscores the state estimator’s proficiency in extracting and integrating box-specific information from the tactile observation history.
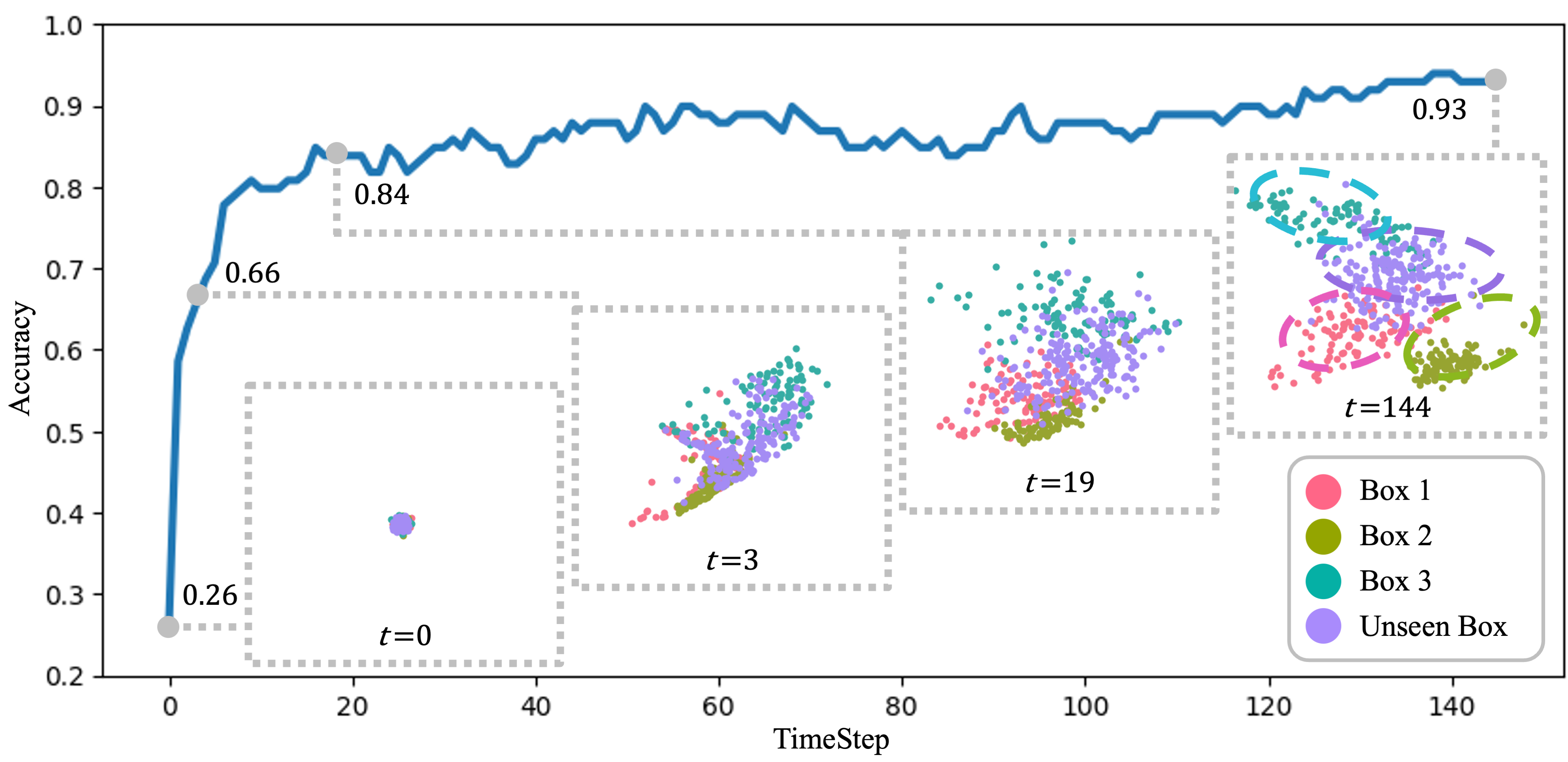
Analysis of learned physics parameters.
Benchmarking Real-World Planning Performance
We first present quantitative results on box pushing. It can be observed that, at every time step, our method is the one that is closest to the goal, indicating that our method is able to consistently find the most efficient pushes.
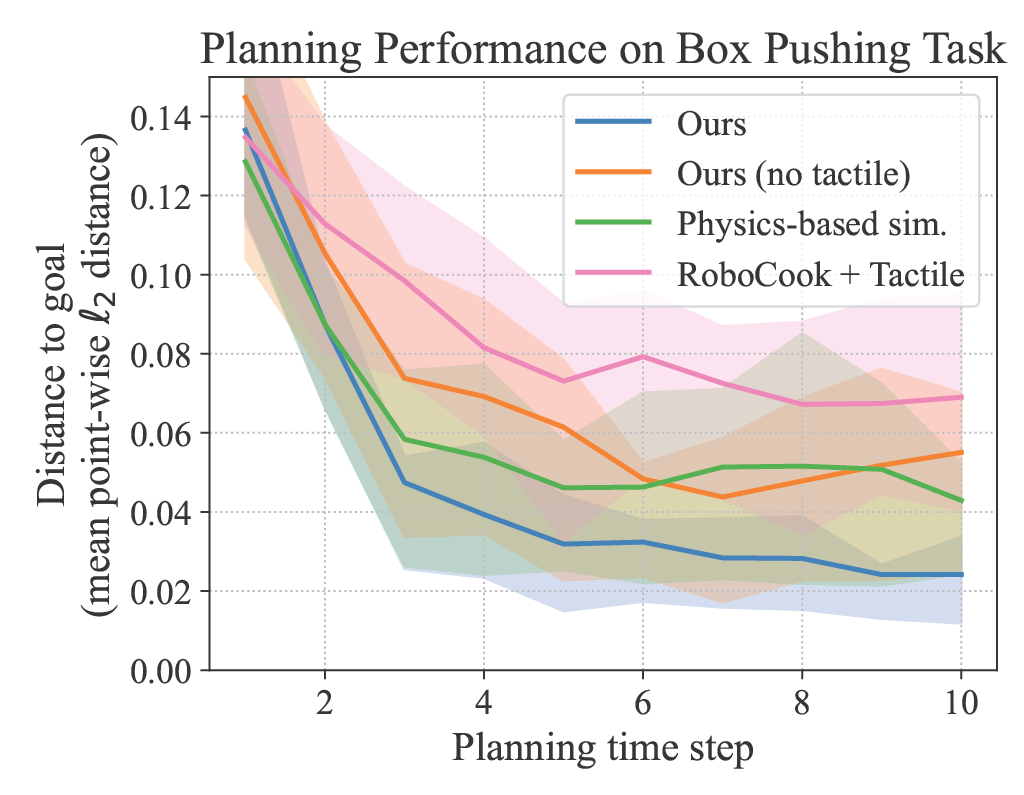
Real-world planning performance on the box pushing task. Shaded regions denote the first and third quantiles.
The table below presents more statistics for the box pushing experiments.

Per-configuration results on the non-prehensile box pushing task.
For the dense packing task, we compare our method against the strongest baseline in the pushing experiments. Our method is able to consistently achieve 2x as high success rate as the baseline across seen and unseen object sets.

Success rates on the dense packing task.
More Qualitative Results
Pushing boxes with various mass distributions using a loosely held tool.
Packing objects into boxes in different layouts.
Conclusion
We presented RoboPack, a framework for learning tactile-informed dynamics models for manipulating objects in multi-object scenes with varied physical properties. By integrating information from prior interactions from a compliant visual tactile sensor, our method adaptively updates estimated latent physics parameters, resulting in improved physical prediction and downstream planning performance. We hope that this is a step towards robots that can seamlessly integrate information with multiple modalities from their environments to guide their decision-making.
BibTeX
@article{ai2024robopack,
title={RoboPack: Learning Tactile-Informed Dynamics Models for Dense Packing},
author={Bo Ai and Stephen Tian and Haochen Shi and Yixuan Wang and Cheston Tan and Yunzhu Li and Jiajun Wu},
journal={Robotics: Science and Systems (RSS)},
year={2024},
url={https://arxiv.org/abs/2407.01418},
}